
The validity of much published scientific research is questionable – so how much trust should we place in it?
An aphorism called the “Einstein Effect” holds that “People find nonsense credible if they think a scientist said it.” We agree, and it’s a major concern as trust in science is near an all-time low. There is a lot of nonsense masquerading as science circulating these days. Unfortunately, as a PEW study released last November indicates, it’s getting worse.
This is part one of a two-part series. Read part two on Tuesday, February 27.
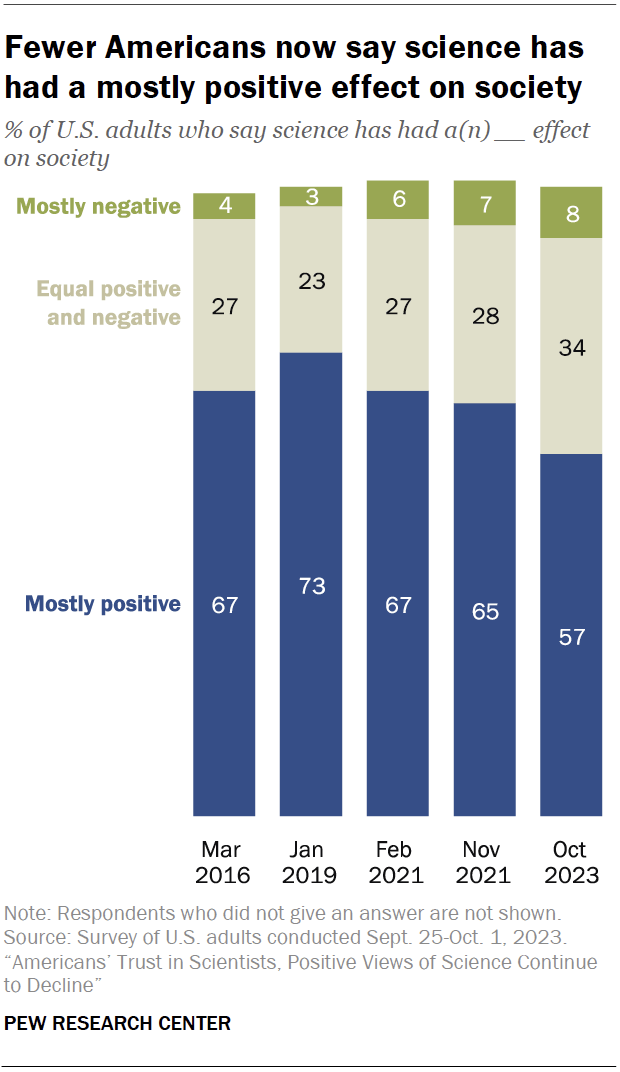
The importance of independent confirmation
Almost five years ago, we wrote about the unreliability of much of the peer-reviewed scientific literature, especially in biomedicine and agriculture. Since then, according to a recent news article in the journal Nature that quantified the problem, the problem is far more significant than even the pessimists had posited.
Corruption is rife. Just last week, the journal Science related that even publishers of prominent scientific journals feel they are “under siege.”: “A spokesperson for Elsevier said every week its editors are offered cash in return for accepting manuscripts. Sabina Alam, director of publishing ethics and integrity at Taylor & Francis, said bribery attempts have also been directed at journal editors there and are 'a very real area of concern.’”
In 2022, the co-chair of the editorial board of the Wiley publication Chemistry–A European Journal received an email from someone claiming to be working with “young scholars” in China and offering to pay him $3000 for each paper he helped publish in his journal. Such dealings have become big business.
This article, and a Part II to follow, address several ways unreliability can occur, purposefully or unintentionally.
Replication challenges
Science is seldom a set of immutable facts; conclusions can and should change as the instruments of interrogation get more sophisticated. Rather, science should be thought of as a method of inquiry – a process — that adjusts the consensus as more and more information is gathered.
Critically, science depends on corroboration — that is, researchers verifying others’ results, often making incremental advances as they do so. The nature of science dictates that no research paper is ever considered the final word, but, increasingly, there are far too many examples of papers in which results are not reproducible.
Why is that happening? Explanations include the increasing complexity of experimental systems, misunderstanding (and often, misuse) of statistics, and pressures on researchers to publish. Of greatest concern is the proliferation of shoddy pay-to-play “predatory” journals willing to publish flawed articles produced by “paper mills,” which perpetrate a kind of industrial fraud prevalent in the publishing sector. They are profit-oriented, shady organizations that produce and sell fabricated or manipulated manuscripts that resemble genuine research.

In 2011 and 2012, two articles rocked the scientific world. One reported attempting to reproduce the results of 53 preclinical research papers considered “landmark” studies. The scientific findings were confirmed in only six (11%) of them. Astonishingly, even the researchers making the claims could not replicate their own work.
The second article found that claims made using observational data could not be replicated in randomized clinical trials (which is why the latter are known as the “gold standard”). Overall, there were 52 claims tested, and none replicated in the expected direction, although most had solid statistical support in the original papers.
Why this divergence? Any number of factors could cause this: the discovery of an unknown effect, inherent variability, different controls, substandard research practices, chance —and increasingly and distressingly, fraud perpetrated in the original or follow-up research by self-interested parties.
More recently, in 2015, 270 co-investigators published the results of their systematic attempt to replicate work reported in 98 original papers from three psychology journals to see how their results would compare. According to the replicators’ qualitative assessments, only 39 of the 100 replication attempts were successful.
That same year, a multinational group attempted to replicate 21 systematically selected experimental studies in the social sciences published in the journals Nature and Science between 2010 and 2015. They found “a significant effect in the same direction as the original study for 13 (62%) studies, and the effect size of the replications is on average about 50% of the original effect size.”
Although these results may seem shocking to the public, which until recently had placed a lot of trust in the findings of scientists, it’s no surprise to scientists themselves. In a 2016 survey of approximately 1500 scientists, 90% said there were major or minor problems with the replication of experiments.
Overly-ambitious or biased science researchers can ‘cook the books’
Failure rates for reports in prominent journals are astonishing — and worrisome because false claims can become canonized and affect the course of future research by other investigators.
Of course, technical problems with laboratory experiments – contamination of cell lines or reagents, unreliable equipment, the difficulty of doing a complex, multi-step experiment the same way time after time, etc. – are one explanation.
Another is statistical sleight-of-hand. One technique for that is p-hacking: Scientists try one statistical or data manipulation after another until they get a small p-value that qualifies as “statistical significance,” although the finding results from chance, not reality.
Australian researchers examined the publicly available literature and found evidence that p-hacking was common in almost every scientific field. Peer review and editorial oversight are inadequate to ensure that articles in scientific publications represent reality instead of statistical chicanery.

Credit: Statistically-Funny.blogpsot.com
This problem in the hard sciences is bad enough, but it’s an epidemic in the social sciences, where everything can be interpreted through a post-modern lens. A variety of studies have explored analytical variability in different fields and found substantial variability among results despite analysts having the same data and research question. If statistical modeling were objective and genuinely predictive, all results should be the same. Notably, peer review did not significantly reduce the variability of results.
Publishers’ bias toward ‘positive’ findings exaggerates the problem
Another problem is that competing scientists often do not retest questions; if they do, they don’t make known their failure to replicate earlier experiments. That leaves significant lacunae, or gaps, in the published literature – which, of course, is produced mostly in universities and is funded by taxpayers.
Many claims appearing in the literature do replicate, but even those are often not reliable. For example, many claims in the psychology literature are only “indirectly” replicated. If X is true, then Y, a consequence, should also be true. Often, Y is accepted as correct, but it turns out that neither X nor Y replicates when tested de novo.
Understandably, editors and referees are biased against papers that report negative results; they greatly prefer positive, statistically significant results. Researchers know this and often do not even submit negative studies – the so-called “file drawer effect.” Once enough nominally positive confirmatory papers appear the claim becomes canonized, making it even more difficult to publish an article that reports a contrary result. This distressing tendency happens in the media as well, which amplifies the misinformation.
A need for humility
The media-academic complex thus undermines the public’s trust, perverts the scientific method, the value of accumulated data, and the canons of science. It makes us wonder whether scientists who practice statistical trickery don’t understand statistics or are so confident of the “correct” outcome that they take shortcuts to get to it.
If the latter, it would bring to mind the memorable observation about science by Richard Feynman, the late, great physicist and science communicator: “The first principle is that you must not fool yourself – and you are the easiest person to fool.”
An unacceptable level of published science and its canonized claims are wrong, sending researchers chasing false leads. Without research integrity, we don’t know what we know. It is incumbent on the scientific community, including government overseers, journal editors, universities, and the funders that support them, to find solutions. Otherwise, the disruption and deception in scientific research will only grow.
Part 2 will address the problems of meta-analyses and scientists buying dubious articles from “paper mills.”
Henry I. Miller, a physician and molecular biologist, is the Glenn Swogger Distinguished Fellow at the American Council on Science and Health. He was the founding director of the FDA’s Office of Biotechnology. Find Henry on X @HenryIMiller
Dr. S. Stanley Young is a statistician who has worked at pharmaceutical companies and the National Institute of Statistical Sciences on questions of applied statistics. He is an adjunct professor at several universities and a member of the EPA’s Science Advisory Board.

Henry I. Miller, MS, MD
Henry I. Miller, MS, MD, is the Glenn Swogger Distinguished Fellow at the American Council on Science and Health. His research focuses on public policy toward science, technology, and medicine, encompassing a number of areas, including pharmaceutical development, genetic engineering, models for regulatory reform, precision medicine, and the emergence of new viral diseases. Dr. Miller served for fifteen years at the US Food and Drug Administration (FDA) in a number of posts, including as the founding director of the Office of Biotechnology.


