
Artificial intelligence is a field of misnomers beginning with its very name. Why it may seem intelligent at its very heart, it is an algorithm using pattern recognition and statistical analysis at speeds allowing it to jettison dead-ends far faster than we could unassisted. The second misnomer is using the term hallucination when programs make data up. In clinical practice, “fixing the data” is a punishable offense and carries academic, if not legal, jeopardy.
One fact about AI that no one argues is that the systems are only intelligent for their training materials – a pure case of garbage in, garbage out. Even when the training materials are of high quality, there can be problems. AI is biased by its training materials. There have been cases in AI interpretation of X-rays where the algorithm used radio-opaque markers inadvertently included in the films to make the diagnosis. There have also been complaints that just as our clinical trials may not be adequately “diverse,” AI training sets are likewise constrained. You need to look no further than the UK’s Biobank data set used in many genomic studies – a dataset that is 90%+ White Brits. Ultimately, the constraints imposed by AI’s learning sets make them “brittle” – all the testing that defines their accuracy, specificity, and sensitivity is for a constrained model under specific circumstances.
AI released into the wild
ChatGPT, one of the more “intelligent” of the algorithms, has already monetized itself. You can get a free version or an upgraded version with a more recent and, therefore, “complete” learning set. Obviously, this learning set will continue moving closer to real-time, and therein lies the first unintended consequence. While the early large language models, another term for the AI algorithms, made use of human knowledge, as more and more of us turn to AI to write papers and reports, more and more of AI’s knowledge will come from AI itself, hallucinations and all.
If AI's intelligence comes from its “out-of-the-box” pattern recognition, then over time, that pattern recognition will have reached its limits, and AI, because its primary source of knowledge will be its own output, will become increasingly self-reinforcing without any diversity at all.
The Sepsis Model
Sepsis is a big problem in hospitalized patients, and for the most part, those patients are cared for in intensive care units that generate lots of data points. The combination of a pressing clinical need and a plethora of already digitalized data made algorithms to identify sepsis an AI long-hanging fruit. EPIC and other vendors provided sepsis algorithms to alert clinicians to the possibility of sepsis as an add-on feature of their systems. Once installed, the algorithm and the hospital’s IT staff, if they had one at all, were left on their own. Stat, in conjunction with MIT researchers, looked at how those models’ performances changed over time; spoiler alert, it ain’t pretty.
The researchers used a dataset of patients admitted to a hospital diagnosed with sepsis. They applied the data available in the hours before the initiation of clinical treatment to two sepsis algorithms. I should immediately note that they did not use the exact sepsis algorithms created by EPIC, merely what was publically known because, in both instances, the algorithm is proprietary, a legally sanctioned black box.
While the initial model had a good diagnostic accuracy, measured by a metric called area under the curve, AUC [1], it degraded over time from a respectable 0.73 to a not particularly helpful 0.60. For comparison, tossing a coin gives you an AUC of 0.50. The cause of the declining accuracy was data drift; the data being supplied to the algorithm was becoming increasingly different than what it had trained on – this is the “brittleness” of AI in the real world.
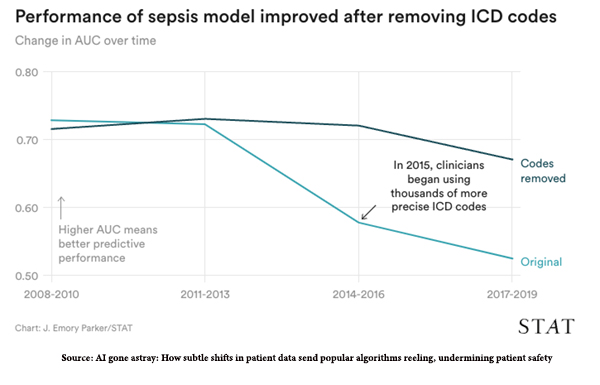 The researchers identified two specific sources of data drift in the sepsis model. First, there were external changes in diagnostic codes as all health facilities transformed their billing from ICD-9 to ICD-10 diagnostic codes. You can see the decline in AUC, the measure of diagnostic accuracy there in 2015, and how removing those new codes restores the accuracy.
The researchers identified two specific sources of data drift in the sepsis model. First, there were external changes in diagnostic codes as all health facilities transformed their billing from ICD-9 to ICD-10 diagnostic codes. You can see the decline in AUC, the measure of diagnostic accuracy there in 2015, and how removing those new codes restores the accuracy.
“When the algorithm was retrained with all ICD codes removed, its drop in performance was less severe, ending .15 higher than the version that included them.”
The second source of data drift was the changing characteristics of patients. During the time frame, the primary hospital absorbed outside facilities, and the patients flowing into the ICU differed. Additionally, the behavior of the onboarding physicians was different, ordering fewer and less timely microbiological samples, a first step in initiating sepsis treatment.
For large hospital systems that can afford a free-standing IT department, it might be possible to monitor the changes in algorithmic performance, but that is a very heavy lift for most hospitals. Maintenance of these systems is not the developers' concern, which is further influenced by the fact that algorithms of this type are considered decision-support tools, not medical devices. That shifts the legal liability away from the developers and onto the tools’ users, the hospital, and clinicians. One advantage of being artificially intelligent is that you are not liable for your “hallucinations;” the human using you carries the legal and financial risk.
Before hospital administrators buy the latest shiny objects to make them seem cutting edge, we must pause and rethink what we are doing. At the very least, we need to clearly identify who, when, and how these algorithms are to be maintained, what is an acceptable lower limit on their diagnostic acumen, and change the liability laws so that everyone, including the developers, has skin in the game.
[1] In the medical field, AUC refers to the area under a receiver operating characteristic (ROC) curve, a graphical representation of a diagnostic test's ability to distinguish between two groups, in this instance, those with or without sepsis. The larger the AUC, the better the test's accuracy.
Source: AI gone astray: How subtle shifts in patient data send popular algorithms reeling, undermining patient safety STAT

Chuck Dinerstein, MD, MBA
Director of Medicine
Dr. Charles Dinerstein, M.D., MBA, FACS is Director of Medicine at the American Council on Science and Health. He has over 25 years of experience as a vascular surgeon.


